

Tecnologias de Vigilância e Antivigilância
Data Brokers e Profiling: vigilância como modelo de negócios
Por Lucas Teixeira | #BoletimConsultas
Esse artigo mostra como empresas “corretoras de dados” compram e vendem informações pessoais em grande escala, para propósitos como prevenção de fraudes, análise de crédito e marketing. Amplamente criticadas em relatórios da Federal Trade Commission e do Senado dos EUA, grandes corporações como a Experian e a Acxiom oferecem produtos que consultam e cruzam bancos de dados para fins como segmentação da população, autenticação de indivíduos e descoberta de tendências comportamentais.
Além disso, o artigo mostra como a técnica de tratamento de dados conhecida como profiling produz dados que, embora não sejam relativos a um titular identificável, como um dado anônimo, ainda assim são sensíveis pois revelam características e tendências a nível supraindividual ou interindividual.
Sob o raciocínio do anteprojeto de lei, o tratamento de dados anônimos e agregados com essa técnica e o subsequente uso das informações apuradas é livre; tais informações, no entanto, podem revelar a origem racial ou étnica, as convicções religiosas e todas as outras características consideradas dados sensíveis a respeito de grupos ouperfis de indivíduos.
Embora nenhum dos documentos peça o fim desse ramo, as críticas às suas atividades são duras. Veja, por exemplo, os títulos das “características da indústria” segundo a FTC (tradução nossa):
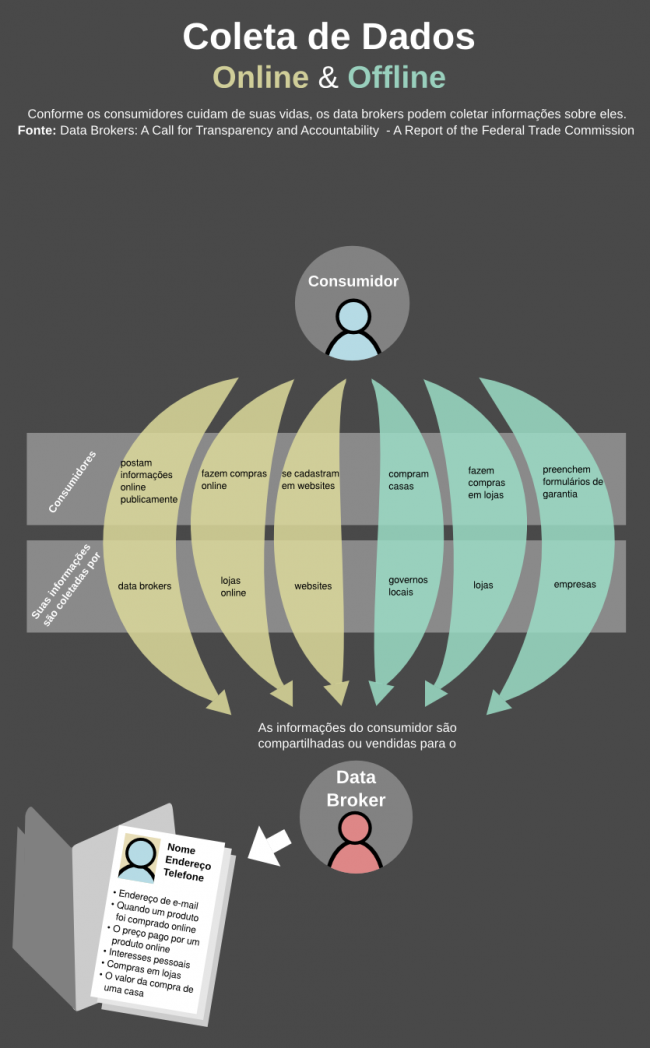
Data brokers coletam dados de várias fontes, muitas vezes sem o conhecimento do consumidor
- A indústria de data broking é complexa, com múltiplas camadas de data brokers provendo dados uma para a outra
- Data brokers coletam e armazenam bilhões de elementos de dados cobrindo quase todo consumidor dos EUA
- Data brokers combinam e analisam dados sobre consumidores para fazer inferências sobre eles, incluindo inferências potencialmente sensíveis
- Data brokers combinam dados online e offline para gerar anúncios para consumidores online
- O documento do Senado reconhece também que data brokers “vendem produtos que identificam consumidores financialmente vulneráveis”, e que “operam sob um véu de obscuridade”.
O documento do Senado reconhece também que data brokers “vendem produtos que identificam consumidores financialmente vulneráveis”, e que “operam sob um véu de obscuridade”.
Serasa Experian
Para entender um pouco melhor como funciona essa indústria no Brasil, analisemos a Serasa Experian. Segundo o site da empresa, ela “é líder na América Latina em serviços de informações para apoio na tomada de decisões das empresas”. Popularmente conhecida por ajudar comércios a evitar fraudes, a Serasa se uniu à Experian, uma das gigantes data brokers do mundo, em 2007.
Um dos serviços de destaque da Experian é o Mosaic, comercializado em 29 países. Sob o slogan “o poder da segmentação ao seu alcance”, o Mosaic Brasil “classifica a população brasileira em 11 grupos e 40 segmentos baseados em aspectos financeiros, geográficos, demográficos, de consumo, comportamento e estilo de vida.”

Um cliente do Mosaic pode obter, por exemplo, uma lista de pessoas em uma determinada região que se encaixam em diferentes perfis pré-determinados: “Seguindo a Vida na Periferia”, “Idosos da Agricultura Familiar do Norte e do Nordeste”, “Adultos Vulneráveis” ou “A Caminho da Aposentadoria nas Melhores Cidades”. Cada uma das pessoas dessa lista, nos bancos de dados da Serasa Experian, carrega consigo variadas informações de valor para o envio de marketing direcionado, como nome, endereço, e possivelmente seu Score de Crédito, um número calculado pela empresa que “indica, de maneira estatística, a probabilidade de inadimplência de determinado grupo ou perfil no qual um consumidor se insere, sem afirmar que ele esteve, está ou ficará inadimplente.”
Usando o InfoMais, um outro serviço da Serasa Experian, é possível “enriquecer” uma base de dados sobre pessoas físicas (clientes de um comércio, por exemplo) e jurídicas com diversas outras informações:

Quem fornece esses dados?
As exatas fontes são desconhecidas – durante as investigações para o relatório do Senado dos EUA, por exemplo, a Experian “se recusou a identificar as fontes específicas de seus dados ou os clientes que os compram”.
O que nos resta é extrapolar os relatórios. Vemos no documento da Federal Trade Commission, por exemplo (grifos nossos):
Nenhum dos nove data brokers [investigados nesse relatório] coletam dados diretamente de consumidores. Em vez disso, eles coletam dados de várias outras fontes, que podem ser divididas em três categorias: (1) fontes governamentais; (2) outras fontes publicamente disponíveis; e (3) fontes comerciais. Embora cada fonte possa prover somente alguns elementos de dados sobre as atividades de um consumidor, os data brokers podem juntar todos esses elementos de dados para formar uma composição mais detalhada da vida do consumidor.
Como o APL nos protege, e como não
O Anteprojeto de Lei para a Proteção de Dados Pessoais nos protege muito bem, em linhas gerais, da coleta e processamento de dados que, segundo o próprio texto da APL, “revelem a origem racial ou étnica, as convicções religiosas, filosóficas ou morais, as opiniões políticas, a filiação a sindicatos ou organizações de caráter religioso, filosófico ou político, dados referentes à saúde ou à vida sexual” (Art. 5.III) da “pessoa natural identificada ou identificável, inclusive a partir de números identificativos, dados locacionais ou identificadores eletrônicos” (Art. 5.I).
Pode haver uma lacuna, no entanto: uma técnica de análise de dados conhecida como profiling permite criar “perfis” virtuais que não identificam ninguém individualmente, mas que são usados para encaixar pessoas em categorias. Essas categorias podem ser previamente determinadas por quem programa o algoritmo – uma abordagem top-down – ou então emergir de correlações feitas cruzando atributos de um ou mais bancos de dados e então interpretados por especialistas ou profissionais da área – bottom-up.
Fernanda Bruno, em seu livro Máquinas de ver, Modos de Ser, define o perfil em termos sociológicos:
O seu principal objetivo não é produzir um saber sobre um indivíduo identificável, mas usar um conjunto de informações pessoais para agir sobre similares. O perfil atua, ainda, como categorização de conduta, visando à simulação de comportamentos futuros. Neste sentido, um perfil é uma alegoria que corresponde à probabilidade de manifestação de um fator (comportamento, interesse, traço psicológico) num quadro de variáveis.
Para ela, tal técnica opera “segundo uma lógica infra ou supraindividual” (grifos nossos):
Infra-individual, porque a informação de interesse (comercial, epistêmico, securitário) não é aquela relativa a um indivíduo específico, mas a parcelas, fragmentos de ações ou comunicações que irão alimentar complexos bancos de dados cujas categorias consistem, por exemplo, em tipos de interesse ou comportamento que não estão atrelados a identificadores pessoais. Ao mesmo tempo, tais bancos de dados mineram essas informações para extrair categorias supraindividuais ou interindividuais a partir de padrões de afinidade e similaridade entre elementos, permitindo traçar perfis – de consumo, interesse, crime, empregabilidade etc. – que irão atuar ou diferenciar indivíduos ou grupos, mas que não dizem respeito a este ou aquele indivíduo especificamente identificável. Tais informações circulam quase que livremente entre diferentes bases de dados (comerciais, administrativas, governamentais, securitárias) e em muitos casos podem não ser consideradas tecnicamente ou juridicamente “dados pessoais”. No entanto, trata-se de informações relativas a indivíduos e que podem ser apropriadas para gerar conhecimento e intervenções sobre eles.
A European Digital Rights, uma associação de dezenas de organizações de defesa de direitos digitais na Europa, nos alerta sobre um dos perigos do uso descontrolado do profiling, principalmente em países que ainda lutam contra a desigualdade econômica e social como o Brasil:
Quase inevitavelmente, os perfis tendem a perpetuar e reforçar a desigualdade social e a discriminação contra minorias raciais, étnicas, religiosas e outras. O profiling pode surtir esses efeitos mesmo se essas informações não forem usadas diretamente. Então, tanto os resultados do profiling quanto seus algoritmos subjacentes devem ser diligentemente monitorados.
Danilo Doneda, professor de Direito da UERJ e Coordenador-Geral de Estudos e Monitoramento de Mercado da Senacon/MJ, também expressa preocupação com as práticas de profiling ao listar algumas considerações para tornar a lei “mais sensível a esse novo paradigma do big data” no Seminário Direito, Tecnologia e Sociedade, diz (grifos nossos):
Tornar mais amplo o conceito de dado pessoal; dado pessoal é um conceito que tradicionalmente é: aquele dado que é referente a uma pessoa identificada ou identificável; hoje em dia, muitos dados que não são sob esse conceito pessoais – são dados estatísticos, são dados aglutinados sobre um grupo de pessoas ou uma família – eles mesmo que não sejam dados pessoais, podem interferir diretamente na vida do indivíduo, eles podem surtir efeitos não só sobre a privacidade dele mas sobre a oferta de determinados serviços, sobre a precificação de determinados bens; enfim, o sujeito hoje em dia pode ser discriminado em relação aos seus dados mesmo que aqueles dados não sejam nominalmente identificados como pertencentes a ele. Então, também no espectro de preocupação com big data, o alargamento do conceito de dados pessoais pra perfis de dados ainda que não nominados e grupos de dados referentes a um grupo de pessoas determinadas também se torna relevante
Propostas de Mudanças
Refletir, na lei, a complexidade e a incerteza da anonimização dos dados. No nosso artigo Teoricamente impossível: problemas com a anonimização de dados pessoais, analisamos problemas graves que resultam de técnicas tradicionais de anonimização frente ao big data.
Inserir “dados socioeconômicos” na lista de dados sensíveis (Art. 5 inc III)
Deixar mais claro que o cancelamento (Art. 5 inc XVI) requer eliminação total dos dados, inclusive de backup e cópias. Uma forma de reescrever o inciso seria “Cancelamento: a eliminação permanente de dados pessoais armazenados em determinado escopo ou local, inclusive de cópias de segurança previamente realizadas”.
Nas exceções ao consentimento: (Art. 11)
-
Definir o que significa “acesso público irrestrito”, uma condição que dispensa o consentimento para tratamento.
-
O tratamento de dados realizado pela administração pública sem necessidade de consentimento (inc. II) deve usar anonimização sempre que possível. O órgão responsável pelo tratamento deve informar o titular sempre que seus dados for utilizado por um órgão diferente ou para outro fim.
-
Remover exceção para “procedimentos pré-contratuais” (inc. III).
-
Remover pesquisas estatísticas das exceções, ou limitá-las para políticas públicas.
Nos direitos do titular: (Art. 17)
-
Inserir dever de informação do cidadão sobre o tratamento de dados no momento de coleta de dados por órgãos públicos, informando onde o cidadão pode ter acesso à política de uso de dados pela administração pública. A informação só é passada quando o dado entra pela primeira vez no sistema.
-
Incluir inciso “V: cancelamento a qualquer momento de dados que o titular tenha fornecido e consentido com o tratamento”.
-
Incluir o direito à portabilidade dos dados. Uma boa inspiração para redação da lei é a emenda sugerida pela EDRi para a Diretiva Europeia de Proteção de Dados (tradução nossa):
1. O titular dos dados deve ter o direito, quando dados pessoais são tratados por meios eletrônicos e em um formato estruturado e comumente utilizado, de obter do operador uma cópia dos dados sendo tratados em um formato eletrônico, interoperável e estruturado que seja comumente usado e permita utilização posterior pelo titular.
2. Quando o titular dos dados houver provido os dados pessoais e o tratamento for baseado no consentimento ou em um contrato, o titular deve ter o direito de transmitir esses dados pessoais e qualquer outra informação provida pelo titular e retida por algum sistema de tratamento automatizado para um outro sistema, em um formato eletrônico que seja comumente utilizado, sem nenhum impedimento do operador de quem os dados foram retirados.
2a. Esse direito não prejudica a obrigação de remover dados quando não são mias necessários no Artigo 5(e).
3. A Comissão [Europeia] pode especificar o formato eletrônico ao qual se refere o parágrafo 1, e as normas técnicas, modalidades e procedimentos para a transmissão de dados pessoais nos termos do parágrafo 2. Essas atividades de implementação devem ser adotadas de acordo com o procedimento de verificação a que se refere oArtigo 87(2).
Responsabilidade dos agentes (Arts. 34 a 38)
Estabelecer que o tratamento de dados pessoais é atividade de risco (Art. 34 ou 35), e deixar explícito que a responsabilidade é objetiva (Art. 35 ), removendo a necessidade de se provar que o dano é imputável (veja detalhes).
Nossa sugestão de nova redação para os artigos 35 e 38 (agradecimentos a Bruno R. Bioni):
Art. 35 O tratamento de dados pessoais é atividade de risco exacerbado e todo aquele que, em razão do exercício de tal atividade, causar a outrem dano patrimonial, moral, individual ou coletivo, é obrigado a ressarci-lo, independentemente de culpa, nos termos desta lei.
§ 1º O operador e os demais agentes que integram a cadeia de tratamento de dados pessoais só não serão responsabilizados havendo culpa exclusiva da vítima ou força maior.
§ 2º O juiz, no processo civil, poderá inverter o ônus da prova a favor do titular dos dados quando, a seu juízo, for verossímil a alegação ou quando a produção de prova pelo titular resultar excessivamente onerosa
[…]
Art. 38 Os órgãos e entidades públicas responderão, independentemente de culpa, pelos danos morais, patrimoniais, individuais ou coletivos causados a outrem decorrentes das gestão das suas bases dados.
§ 1º As competências quanto à gestão de base de dados nos órgãos e entidades públicas serão definidas em atos normativos, sem prejuízo da responsabilidade civil objetiva do Estado por danos oriundos de tal atividade, conforme estabelecido no dispositivo anterior.
Biblografia
Agradecimento
O episódio #52 do podcast Segurança Legal, “DataBrokers, Privacidade e Discriminação”, foi uma enorme inspiração para esse artigo.
Acesse outros conteúdos publicados no “Edição Especial Consultas Públicas do boletim Antivigilância” acessando a tag “boletimConsultas” abaixo.