

Privacidade e Políticas Públicas
Teoricamente impossível: problemas com a anonimização de dados pessoais
2015-12-05: Este artigo foi feito baseado na versão antiga do Anteprojeto de Lei de Proteção de Dados Pessoais. A nova versão contém mudanças significativas e positivas na abordagem da anonimização de dados, motivadas em parte por esta própria análise.
Por Lucas Teixeira | #BoletimConsultas
Quando uma regulamentação vem faceiramente determinar que alguns dados são “anônimos” ou mesmo “pseudônimos”, essa regulamentação está gritantemente desconectada das melhores teorias de que dispõe a ciência da computação.
– Cory Doctorow

No texto da APL
Art. 5º Para os fins desta Lei, considera-se:
[…] IV – dados anônimos: dados relativos a um titular que não possa ser identificado, nem pelo responsável pelo tratamento nem por qualquer outra pessoa, tendo em conta o conjunto de meios suscetíveis de serem razoavelmente utilizados para identificar o referido titular;
[…] XIV – dissociação: ato de modificar o dado pessoal de modo a que ele não possa ser associado, direta ou indiretamente, com um indivíduo identificado ou identificável;
Para entender melhor, imagine a seguinte tabela no computador de um consultório médico:
| CPF | Nome | Etnia | Nascimento | Sexo | CEP | Sintoma |
|---|---|---|---|---|---|---|
| 955.818.3-10 | Jean | Negra | 09/20/1965 | Masculino | 21500-141 | Respiração curta |
| 011.346.3-40 | Daniel | Negra | 14/02/1965 | Masculino | 21500-141 | Dor de barriga |
| 384.345.3-81 | Karina | Negra | 23/10/1965 | Feminino | 21500-138 | Dor nos olhos |
| 949.262.3-44 | Maria | Negra | 24/08/1965 | Feminino | 21500-138 | Coriza |
| 853.002.3-66 | Helena | Negra | 07/11/1964 | Feminino | 21500-138 | Dor nas juntas |
| 661.691.3-56 | Rose | Negra | 01/12/1964 | Feminino | 21500-138 | Dor de barriga |
| 396.891.3-26 | Flávio | Branca | 23/10/1964 | Masculino | 21500-138 | Respiração curta |
| 084.568.3-30 | Larissa | Branca | 15/03/1965 | Feminino | 21500-139 | Hipertensão |
| 490.981.3-00 | Filipe | Branca | 13/08/1963 | Masculino | 21500-139 | Dor nas juntas |
| 993.538.3-86 | Jeremias | Branca | 05/05/1964 | Masculino | 21500-139 | Febre |
| 603.200.3-78 | Jean | Branca | 13/02/1967 | Masculino | 21500-138 | Vômitos |
| 878.939.3-14 | Adriano | Branca | 13/02/1967 | Masculino | 21500-138 | Dor nas costas |
No jargão da ciência da computação, cada linha dessa tabela contém um dados de sobre uma pessoa natural, e cada coluna representa valores de um atributo (CPF, nascimento, sintoma).
Divulgar essa tabela sem consentimento é uma tremenda quebra de sigilo médico, e da privacidade das pessoas descritas de maneira geral.
É fácil entender que a coluna CPF, e talvez a coluna nome, podem ser usadas para identificar os indivíduos da tabela, e então enviar propagandas personalizadas, ou ajustar o valor de seu plano de saúde, por exemplo. Uma primeira tentativa de anonimizar esses dados seria eliminar essas duas colunas – os dados sensíveis:
| CPF | Nome | Etnia | Nascimento | Sexo | CEP | Sintoma |
|---|---|---|---|---|---|---|
| 000.000.0-00 | — | Negra | 09/20/1965 | Masculino | 21500-141 | Respiração curta |
| 000.000.0-00 | — | Negra | 14/02/1965 | Masculino | 21500-141 | Dor de barriga |
| 000.000.0-00 | — | Negra | 23/10/1965 | Feminino | 21500-138 | Dor nos olhos |
| 000.000.0-00 | — | Negra | 24/08/1965 | Feminino | 21500-138 | Coriza |
| 000.000.0-00 | — | Negra | 07/11/1964 | Feminino | 21500-138 | Dor nas juntas |
| 000.000.0-00 | — | Negra | 01/12/1964 | Feminino | 21500-138 | Dor de barriga |
| 000.000.0-00 | — | Branca | 23/10/1964 | Masculino | 21500-138 | Respiração curta |
| 000.000.0-00 | — | Branca | 15/03/1965 | Feminino | 21500-139 | Hipertensão |
| 000.000.0-00 | — | Branca | 13/08/1963 | Masculino | 21500-139 | Dor nas juntas |
| 000.000.0-00 | — | Branca | 05/05/1964 | Masculino | 21500-139 | Febre |
| 000.000.0-00 | — | Branca | 13/02/1967 | Masculino | 21500-138 | Vômitos |
| 000.000.0-00 | — | Branca | 13/02/1967 | Masculino | 21500-138 | Dor nas costas |
O que se verifica, porém, é que dados aparentemente inócuos podem ser combinados para identificar uma pessoa. Um estudo clássico é o que Latanya Sweeney conduziu em 2000, cruzando dados públicos do censo dos EUA:
Foi descoberto que 87% (216 milhões de 248 milhões) da população dos EUA tem características relatadas que provavelmente as tornam únicas com base somente em {código ZIP de 5 dígitos [equivalente ao CEP brasileiro], gênero, data de nascimento}. Cerca de metade da população dos EUA (132 milhões de 248 milhões ou 53%) devem ser unicamente identificáveis somente por {local, gênero, data de nascimento}, onde o local é basicamente a cidade ou município onde a pessoa reside. (tradução e grifo nossos)
Um outro estudo mais recente, do MIT Media Lab, mostra que dados sobre compras com o cartão também podem formar padrões únicos, como reporta o jornal El País:
“Com uma média de quatro transações, o dia e a loja é suficiente para identificar de forma exclusiva as pessoas em 90% dos casos”, diz o pesquisador do MIT e coautor do estudo, Yves-Alexandre de Montjoye. “A lógica subjacente reside em que muitas pessoas compram algo em uma determinada loja (C&A, por exemplo) em um dia determinado (digamos, ontem). Entretanto, só algumas delas também comprarão em determinado Walmart nesse mesmo dia. E ainda menos irão comer no dia seguinte na mesma região. Quando você sabe quatro lugares ou lojas e dias, em 90% das vezes há uma e só uma pessoa em toda a base de dados que compra algo em quatro lugares nesses quatro dias”, explica. (grifo nosso)
Algumas pessoas chamam esses atributos de “quasi-identificadores”, como Ann Cavoukian e Daniel Castro em sua defesa da anonimização de dados:
o problema da anonimização envolve quasi-identificadores, aquelas variáveis que podem não identificar indivíduos diretamente, mas que têm uma correlação muito alta com identificadores únicos e ainda podem ser usadas para re-identificação indireta. Esses quasi-identificadores são úteis tanto em si mesmos quanto combinados com outras informações disponíveis para identificar unicamente indivíduos. (tradução nossa)
Mas, de acordo com a ciência da computação, tal distinção entre quasi-identificadores e todo o resto dos dados é arbitrária – todo tipo de informação sobre indivíduos pode ser usada para a re-identificação – ou associação, se seguirmos o espírito da nomenclatura do anteprojeto brasileiro. Como dizem Arvind Narayanan e Vitaly Shmatikov:
Algoritmos de re-identificação são agnósticos quanto à semântica dos elementos de dados. Acontece que há um amplo espectro de características humanas que permitem a re-identificação: preferências de consumo, transações comerciais, navegação web, históricos de busca, e por aí vai. Suas duas propriedades-chave são que (1) elas são razoavelmente estáveis através do tempo e de contextos, e que (2) os atributos de dados correspondentes são suficientemente numerosos e detalhados para que seja muito improvável encontrar duas pessoas similares.
A versatilidade e o poder dos algoritmos de re-identificação fazem com que termos como “pessoa identificável” ou “quasi-identificador” simplesmente não tenham significado técnico. Enquanto alguns atributos podem ser identificadores únicos por si próprios, qualquer atributo pode ser um identificador em combinação com outros. Considere, por exemplo, os livros que uma pessoa leu ou até mesmo as roupas em seu armário: embora nenhum único elemento seja um (quasi)-identificador, qualquer subconjunto suficientemente grande identifica um indivíduo unicamente. (tradução nossa)

Arvind Narayanan também mantém um blog, 33 Bits of Entropy, onde publica artigos próprios e analisa o trabalho de outros pesquisadores em torno do fato “de que há somente 6,6 bilhões de pessoas no mundo, então só são necessários 33 bits de informação sobre uma pessoa para determinar quem ela é”.
Esse fato tem duas consequências relacionadas. Primeiro, muito do pensamento tradicional sobre dados anônimos se apoiou no fato de que é possível se esconder em uma multidão grande demais para se fazer uma busca. Esse conceito desmorona dado o poder computacional atual: contanto que o vilão tenha informações suficientes sobre seu alvo, ele pode simplesmente analisar item por item no banco de dados e escolher o que melhor se encaixa.
A segunda consequência é que 33 bits não é muita coisa. Se sua cidade natal tem 100.000 habitantes, então saber em que cidade você nasceu me dá 16 bits de entropia sobre você, restando 17 bits. Mas o perigo real é que informações sobre o comportamento de uma pessoa, que tradicionalmente não são pensados como dados identificáveis, podem ser usados para causar sérias violações de privacidade em uma variedade de contextos.
– About 33 Bits of Entropy (tradução nossa)
Akinator, “o Gênio da Internet”, é um jogo online que ilustra bem essas consequências:
Trata-se de um game no qual um gênio virtual é capaz de adivinhar o personagem em que o jogador está pensando, seja ele real ou fictício, através de uma série de perguntas sobre suas características.
[…] Com um banco de dados imenso, o jogo funciona através de perguntas de eliminação. O gênio vai eliminando todas as possibilidades até sobrar apenas um resultado que atenda às repostas dadas pelo jogador.
Uma das intuições sobre como funciona o “truque” do gênio […] diz respeito à representação. Isto é, cada pessoa/personagem/coisa no jogo é representado por um ponto num espaço n-dimensional em que cada dimensão representa a presença ou ausência de uma característica, se ele é branco ou se é homem, por exemplo. A cada pergunta respondida esse espaço vai sendo restringindo.

O Akinator adivinhou, através das perguntas à direita, que a pessoa pensada é Edward Snowden
O Banco de Dados da Ruína
Em seu artigo “Broken Promises of Privacy”, Paul Ohm explica a história da anonimização de dados e como leis modernas interpretam “dados pessoais sensíveis”; analisa alguns casos notórios de re-identificação e dá conselhos para legisladores na criação de novas regulamentações.
Ele tem uma visão alinhada com a de Narayanan e Shmatikov, e alerta sobre o accretion problem, ou “problema do crescimento”:
A partir do momento em que um adversário linkou dois bancos de dados anonimizados, ele pode adicionar os novos dados linkados para sua coleção de informações externas e usá-los para destravar outros bancos de dados anonimizados. […] É por isso que devemos nos preocupar até mesmo com situações de re-identificação que só parecem expôr informações triviais, pois elas aumentam a linkabilidade dos dados, e assim expõe as pessoas a um potencial dano futuro. (tradução nossa)
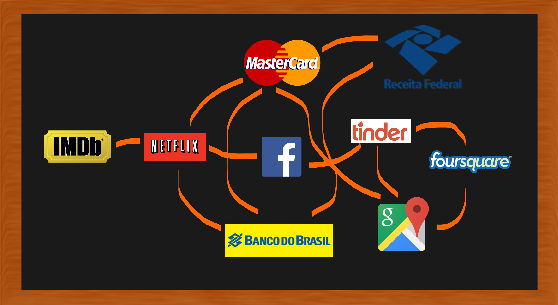
É como se a re-identificação e o problema do crescimento juntassem os dados de todos os bancos de dados do mundo em um único, gigante, banco-de-dados-no-céu, um alvo irresistível para pessoas mal intencionadas. Reguladores devem se importar com a ameaça de prejuízo da re-identificação porque esse banco-de-dados-no-céu contém informações sobre todo o mundo.
Quase todas as pessoas no mundo desenvolvido podem ser ligadas a pelo menos um fato em um banco de dados de computador que uma pessoa adversária pode usar para chantagem, discriminação, assédio, ou roubo financeiro e de identidade. Quero dizer mais que mero constrangimento ou inconveniência; quero dizer danos legalmente reconhecíveis. Talvez seja um fato sobre uma conduta anterior, sobre saúde, ou algo envergonhador perante a família. Para quase cada um de nós, então, podemos imaginar um hipotético banco de dados da ruína, aquele que contém esse fato, mas que até agora está fragmentado em dezenas de bancos de dados em computadores ao redor do mundo, e então desconectados da nossa identidade. A re-identificação formou o banco de dados da ruína e concedeu acesso aos nossos piores inimigos. (tradução nossa)
Através de uma metáfora criativa, Paul Ohm mostra um problema que enxerga em regulamentações contemporâneas:
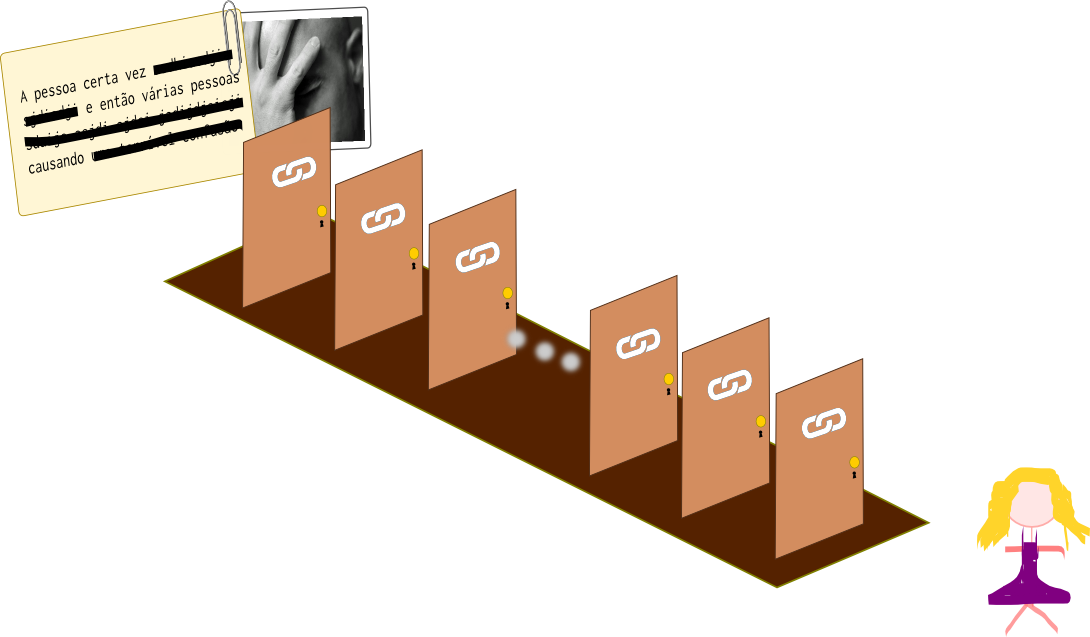
Ilustração da metáfora de Paul Ohm para o “banco de dados da ruína”
Imagine que cada pessoa viva está de um lado de um longo corredor dedicado somente à ela. Do outro lado desse corredor está o fato arruinador daquela pessoa, o segredo que uma pessoa inimiga poderia usar para causá-la muito prejuízo. No corredor entre a pessoa e o fato arruinador, imagine uma longa série de portas fechadas e trancadas, e em que cada cadeado requer uma chave diferente, que representa os atributos de banco de dados que devem ser reconectados ou os links na cadeia de inferências que devem ser estabelecidos para conectar a pessoa ao fato. Finalmente, imagine muitas outras pessoas segurando chaves para algumas das portas. Cada pessoa representa a dona de um banco de dados, e as chaves que segura representam as inferências que ela pode fazer, usando os dados que possui.
Sob a atual, agora desacreditada abordagem de “dados pessoais identificáveis” para regulamentar a privacidade, tendemos a responsabilizar as pessoas que administram um banco de dados – as que estão no meio do corredor – pela proteção da privacidade somente se por acaso possuírem uma das duas chaves críticas [a primeira e a última]. […] tendemos a imunizar todos os proprietários de bancos de dados cujas chaves desbloqueiam só portas no meio do corredor (tradução nossa)
Em outra seção, ele parte da metáfora para uma recomendação:
Seria logicamente justificável, mas por demais agressivo, regulamentar qualquer entidade que possui qualquer fragmento de informação em qualquer ponto da cadeia de inferências, cobrindo até mesmo alguém que possui uma única chave. Devemos direcionar os recursos escassos de regulamentação àquelas entidades que mais contribuem para o risco do banco de dados da ruína, através de regras bem afinadas. (tradução nossa)
Ohm então propõe uma categoria para o que no APL é chamado de operador de tratamento de bancos de dados, os “grandes redutores de entropia”:
Grandes redutores de entropia são entidades que acumulam bancos de dados massivos que contém tantas associações entre tantos tipos diferentes de informação que elas representam uma parte significativa do banco de dados da ruína, mesmo que eles removam de seus bancos de dados todas as informações particularmente sensíveis e diretamente associáveis.
Quem são os grandes redutores de entropia? Na metáfora do corredor, são as pessoas segurando muitas chaves; imagine o chaveiro do lendário zelador, tilintando com dezenas de chaves diferentes. Na prática, essa categoria inclui grandes agências de crédito como Experian, TransUnion, e Equifax; corretores comerciais de dados como ChoicePoint, Acxiom e LexisNexis; e provedores de busca na Internet como Google, Microsoft e Yahoo. (tradução nossa)

A Tragédia dos Dados Comuns
A essa altura, não parece haver motivos fortes para autorizar a anonimização de dados. Mas através de um paralelo com a Tragédia dos Comuns, aquele texto famoso que fala sobre bosques, extração de recursos e como o individualismo atrapalha a vida comunitária, Jane Yakowitz constrói um paradigma onde a divulgação de bancos de dados anonimizados de hospitais, escolas, órgãos públicos e outras instituições tornam possível para o público em geral conduzir investigações e pesquisas que beneficiam a sociedade:
[…] [dados para pesquisa] estão em grande necessidade de proteção. As pessoas começaram a defensivamente guardar informações anonimizadas sobre elas. Estamos testemunhando um exemplo moderno da tragédia dos comuns. Cada uma delas tem um incentivo para remover seus dados dos comuns para evitar riscos remotos de re-identificação. Dessa maneira ela tem o melhor dos dois mundos: seus dados estão a salvo, e ela também recebe os benefícios indiretos da pesquisa médica e política conduzida no resto dos dados deixados nos comuns. No entanto, esse benefício coletivo derivado dos comuns de dados vão degenerar rapidamente se os sujeitos desses dados os removerem para se proteger.
[…] Se a anonimização de dados for pensada como impossível, o futuro dos dados abertos e de toda a utilidade social que flui por eles vai ser posta em questão. Quase todos os debates recentes de políticas públicas se beneficiou da disseminação em massa de dados anônimos.

Yakowitz também critica alguns argumentos mais alarmantes sobre re-identificação, apresenta técnicas mais avançadas de anonimização e uma proposta minimalista de regulamentação:
Sob a ótica do meu paradigma, uma entidade que produz dados é obrigada a fazer somente duas coisas para converter dados que identificam pessoas em dados anonimizados: (1) retirar todos os identificadores diretos, e (2) ou checar por tamanhos mínimos de subgrupos em uma lista pré-estabelecida de identificadores diretos comuns – como etnia, sexo, indicadores geográficos e outros identificadores indiretos comumente encontrados em registro públicos – ou usar um quadro de amostragem aleatório eficaz.
No Brasil, esse commons de dados é alimentado por grupos como o Transparência Hacker e projetos governamentais como o Portal Brasileiro de Dados Abertos. Resta o desafio, então: como regulamentar a publicação de dados anonimizados de forma a permitir pesquisas científicas e políticas públicas, mas impedir os riscos da reidentificação e o fantasma do banco de dados da ruína?
Arvind Narayanan e Edward Felten, em um um artigo publicado três anos após o de Yakowitz, argumentam que não há uma fórmula mágica (tradução nossa):
A privacidade dos dados é um problema difícil. Os guardiões de dados devem fazer uma escolhe entre, a grosso modo, três alternativas: continuar com o antigo hábito de dissociação e torcer pelo melhor; adotar tecnologias emergenciais como a differential privacy que involvem alguns compromissos de utilidade e conveniência; ou usar acordos legais para limitar o fluxo e o uso de dados sensíveis. Essas soluções não são completamente satisfatórias tanto individualmente quanto combinadas, e nenhuma das abordagens é a melhor em todas as circunstâncias.
Dados sensoriais e de localização: dá para se esconder na multidão?

Uma área bastante delicada é a dos dados de localização, emitidos por exemplo pelo GPS de smartphones e carros, mas até mesmo por um aparelho celular tradicional (o dumbphone) através da triangulação com as antenas mais próximas.
Em 2011, Hui Zang e Jean Bolot publicaram um estudo de nome sugestivo: “A Anonimização de Dados de Localização Não Funciona: Um Estudo de Medidas de Larga-escala”. Nele, Hui e Jean “examinam um conjunto de dados de escala muito grande, com mais de 30 bilhões de registros de chamada feito por 25 milhões de celulares em todos os 50 estados dos EUA, e tentam determinar até que ponto dados de localização anonimizados podem revelar informações sobre as pessoas que usam o serviço.”: (traduções e grifos nossos):
Nosso estudo mostra que compartilhar dados de localização anonimizados provavelmente levará a riscos de privacidade, e que, no mínimo, os dados precisam ser menos específicos, ou no domínio do tempo (ou seja, os dados são coletados em curtos períodos de tempo, e então inferir o top N de localizações de forma confiável é difícil) ou no domínio do espaço (ou seja, a granularidade dos dados é sempre estritamente maior que o nível da célula). Em ambos os casos, a utilidade dos dados de localização anonimizados diminuirá, talvez consideravelmente.
Já no ano passado, 2014, três pessoas da área de pesquisa da SAP, uma empresa de software, e da Universidade Nacional da Singapura, fizeram um estudo sobre “o risco de re-identificação de trajetórias em dados de mobilidade humana baseados em um grande conjunto de dados de mais de meio milhão de indivíduos durante um período de uma semana.”: (traduções e grifos nossos):
Descobrimos que indivíduos são altamente re-identificáveis com apenas alguns pontos espaço-temporais. Nós propromos uma abordagem simples de anonimização para modificar o conjunto de dados encurtando as trajetórias. Examinando o quão únicos são esses dados, concluímos que técnicas de anonimização podem melhorar a proteção à privacidade e reduzir os riscos de re-identificação e vazamento dos informacões, embora os dados anonimizados não possam fornecer anonimato total.
Os dados sensoriais e dados biométricos também são complexos de se anonimizar. Um terceiro estudo feito pela Microsoft Research Asia e a Universidade de Ciência e Tecnologia da China em 2012 analisa “a viabilidade da re-identificação de pessoas através de bases de dados sensoriais rotineiramente coletadas em dispositivos comuns no mercado (por exemplo, smartphones)”: (traduções nossas)
Resultados preliminares do nosso estudo sugerem que os mesmos desafios de manter o anonimato de uma pessoa – que foram verificados inclusive em conjuntos de dados de notas de avaliação de filmes e históricos de compras – provavelmente existem quando dados sensoriais são compartilhados. Nossas descobertas indicam que mais estudos sobre esse problema são necessários.
Propostas de mudanças
Mudar ocorrências de “dissociação” para “anonimização”: a dissociação é apenas uma das formas de anonimizar bancos de dados. A palavra ocorre nos seguintes trechos:
-
Art. 5º inc XIV
-
Art. 11º inc IV
-
Art. 12º inc II.b
-
Art. 15º inc II
-
Art. 17º inc IV e §5
-
Art. 50º inc III
Mudar ocorrências de “dados anônimos” para “dados anonimizados”. Como mostramos nesse artigo, o conceito de “dado anônimo” é extremamente elusivo em um cenário de big data. A disponibilidade cada vez maior de grandes bancos de dados e o aprimoramento das técnicas de cruzamento e reidentificação fazem com que mesmo que um banco de dados anonimizado hoje possa ser reidentificado no futuro próximo. Essa é uma medida para refletir essa condição técnica para futuros juristas que venham a interpretar a lei.
Elevar dados anonimizados à categoria de dados pessoais. Apontar na definição que é um dado pessoal que passou por processo de anonimização, e criar uma exceção de consentimento (Art. 11º) para a coleta (mas não a transferência) desse tipo de dados. Acreditamos que essa última medida mantém a utilidade desses dados para pesquisa e estatísticas internas sem enfraquecer a legislação ou permitir o crescimento dos “bancos de dados da ruína” de Paul Ohm. Uma loja ou organização poderia coletar esses dados anonimizados para uso próprio, por exemplo, mas não vendê-los para data brokers.
Estabelecimento de “boas práticas” fortes e constantemente atualizadas para a anonimização. A definição de “dados anônimos” do APL leva em conta “o conjunto de meios suscetíveis de serem razoavelmente utilizados para identificar o referido titular”. Como vimos, os meios de identificação estão em constante desenvolvimento, e dependem fundamentalmente do acesso a outros bancos de dados, de uma forma impossível de ser mensurada. Essa “razoabilidade” então deverá ser redefinida periodicamente pela autoridade com base nos últimos avanços da matemática e da ciência da computação.
Proibir incondicionalmente a re-identificação de dados anonimizados.
Bibliografia
Créditos das imagens
-
Fotografia Facepalm, por brandongrasley – licença Creative Commons Attribution 2.0 Generic)
-
Fotografia Mobility, por Matthias Ripp – licença Creative Commons Attribution 2.0 Generic)
-
Diversas imagens do Openclipart