

Tecnologías de Vigilancia e Antivigilancia
Data Selfie: ¿qué tipo de algoritmos queremos?
Por Hang Do Thi Duc | #Boletim16
Data Selfie, como una herramienta de activismo de datos, es una extensión de navegador de código abierto y gratuito que te rastrea en Facebook: lo que miras, cuánto tiempo lo miras, lo que te gusta, los enlaces en los que hace clic en las historias destacadas, además de lo que escribes.
Con esa información, presenta un tablero de tu uso, un análisis de las imágenes que consumes y predicciones (basadas en los datos rastreados) que son proporcionadas por los algoritmos de aprendizaje automático de IBM Watson y el Centro de Psicometría de la Universidad de Cambridge. Esto incluye información muy sensible como un perfil de personalidad (OCEAN/Big 5, es decir, apertura a la experiencia, responsabilidad, extroversión, amabilidad e inestabilidad emocional), orientación religiosa y política, satisfacción con la vida y potencial de liderazgo. Es una demostración del tipo de información que Facebook podría estar aprendiendo sobre las y los usuarios.
En una nota más técnica: esta herramienta no usa la API de Facebook, ya que no da acceso a datos muy granulares, como cuánto tiempo ha visto una publicación. La extensión mira al front-end representado (el DOM) de la página de Facebook del usuario en el navegador (los elementos HTML y su contenido) y con JavaScript la extensión del navegador puede detectar cuándo la persona se desplaza por el sitio, cuándo escribe y cuándo hace clic en algo. La extensión proporciona a los usuarios de Facebook 1 el tipo de datos que Facebook podría rastrear sobre ellos y el tipo de información sobre la personalidad que Facebook podría estar generando sobre ellos mediante el uso de algoritmos de aprendizaje automático. Este no es un esfuerzo para aplicar ingeniería inversa o replicar el algoritmo de Facebook, solo es un intento de mostrar lo que es posible con los algoritmos disponibles.
Además, los permisos que solicita la extensión son para procesamiento de datos de forma local (en tu máquina) y envío de solicitudes anónimas al servidor de Data Selfie. Esto significa que los datos de consumo se envían sin la identidad de las personas (por ejemplo, nombre o ID de Facebook) al servidor, y el análisis (por ejemplo, predicción de la personalidad) se envía de vuelta al tablero de la extensión del usuario. No se conservan registros (no hay base de datos, no hay logs) en el servidor de los datos enviados (input) ni en sus resultados de análisis (output). El servidor mantiene las direcciones IP durante 24 horas para asegurarse de que nadie abuse del servicio gratuito con demasiadas solicitudes.
El arte y el diseño pueden ayudar a las personas a ver cosas que antes no eran capaces de ver, a comprender una perspectiva que no habían comprendido antes. Es el motivo principal de este artístico producto anti-producto. A primera vista, esto podría parecerse a la próxima start up que resolverá su modelo de ingresos luego («probablemente anuncios publicitarios», algunos pensarán). Pero no somos empresarias y no estamos buscando monetizar esto. No se almacenan datos de las y los usuarios. No hay estrategias para mantener a las y los usuarios comprometidos; está más que bien si lo desinstalan, de hecho, ayudaría a mantener bajos los costos. No hay interfaz «amigable para el usuario»; la estética terminal se supone que se siente cruda y al estilo hacker.
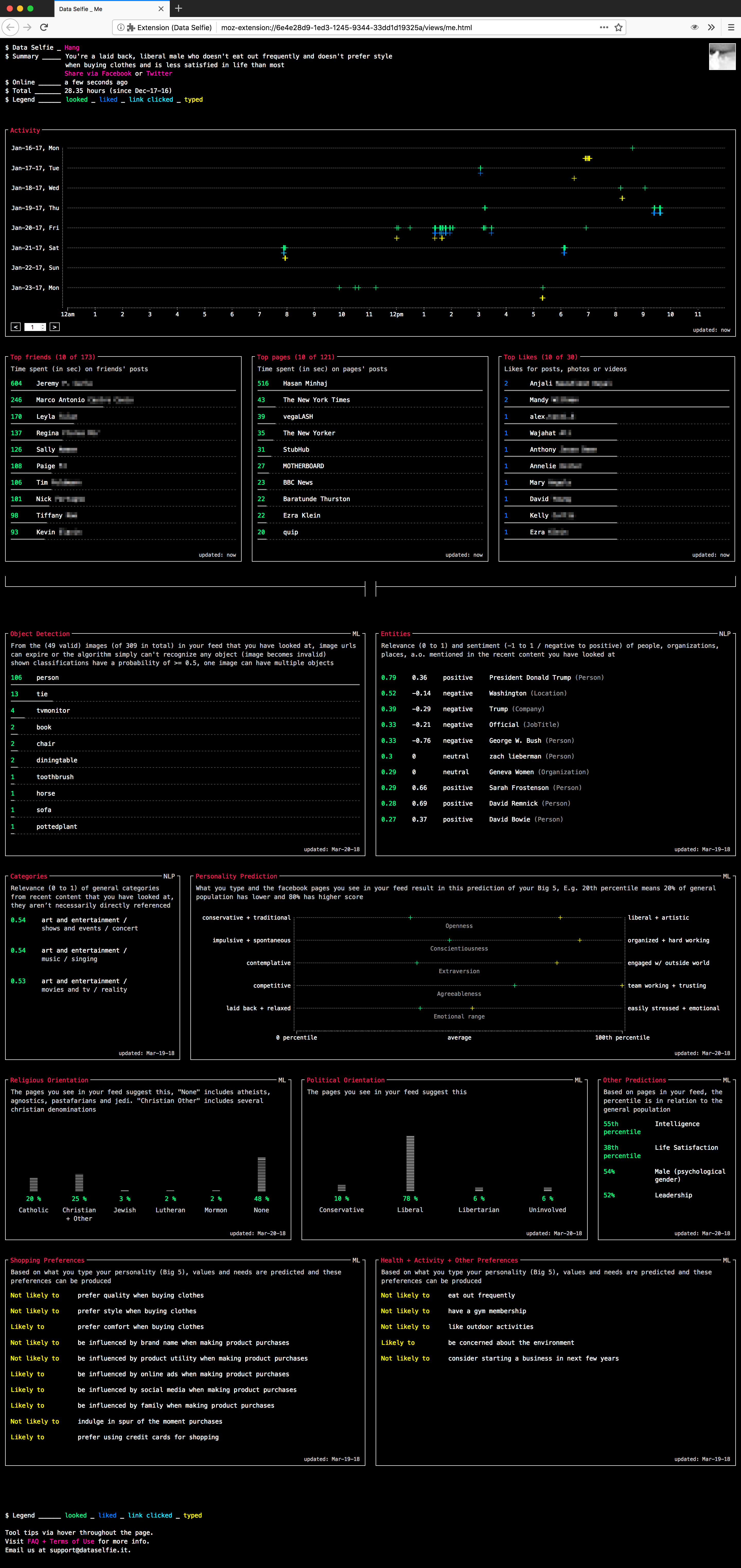
Captura de pantalla de Data Selfie
En muchos sentidos, Data Selfie no responde a preguntas como lo hacen los productos reales, sino que esta investigación creativa provoca nuevas preguntas: ¿Qué pueden (otras) empresas saber de mí? ¿Qué tipo de algoritmos queremos? Data Selfie nos obliga a pensar y discutir cuánto control realmente tenemos sobre nuestros datos. El Reglamento General de Protección de Datos (RGPD) de la Unión Europea, aplicable en 2018, incluye artículos que dan a las personas el derecho a estar informados y acceder, restringir y borrar sus datos personales gestionados por las empresas. Tanto Data Selfie como esta ley abordan el conocimiento y el desequilibrio de poder actualmente en juego.
Si no hay anuncios publicitarios, ¿cómo se financia la herramienta? Data Selfie recibió fondos de la Corporación de Desarrollo Económico de la Ciudad de Nueva York, la Oficina de la Alcaldía de Medios y Entretenimiento, y el Laboratorio de Medios de la Ciudad de Nueva York a través del programa Combine en el 2016. Los continuos costos de API y los esfuerzos de mantenimiento, además del desarrollo de nuevas prestaciones, son cubiertos gracias a un Flash Grant de la Fundación Shuttleworth y una Media Grant de la Fundación Mozilla, con el apoyo (en parte) de una subvención de Open Society Foundations.
Hay un gran atractivo para explorar la sociedad y la cultura a través de los datos. Es fascinante ver las perspectivas que los datos pueden revelar. Al mismo tiempo, es problemático cuando las corporaciones (y los gobiernos) son opacos sobre lo que aprenden de nosotros a través de nuestros datos autogenerados, especialmente cuando los usan de formas que la mayoría de nosotros desconoce.
Los últimos 2 años mostraron que en nuestra sociedad de datos los algoritmos son omnipresentes y, aparentemente, omniscientes y omnipotentes, no obstante, aún ocultos. Sin embargo, es obvio que los algoritmos de Big Data definen cada vez más nuestras vidas y es importante, especialmente para aquellos que son indiferentes a este tema, ser conscientes del poder y la influencia de nuestros datos sobre nosotros mismos.
1. Ha habido una amplia discusión sobre cómo Cambridge Analytica podría haber utilizado la psicometría en sus esfuerzos en el referéndum Brexit y en las elecciones de los EE.UU. en el 2016. No tenemos conexión con esta empresa y nunca la tendremos. El Centro de Psicometría de la Universidad de Cambridge ha publicado una declaración para aclarar que no están afiliados de ninguna manera con Cambridge Analytica.
Hang Do Thi Duc actúa como diseñadora-artista-tecnóloga y es cocreadora de Data Selfie.